
The nightmare scenario of no new particles or interactions at the LHC is coming true. And it might be our own fault.
Over at the Large Hadron Collider, protons simultaneously circle clockwise and counterclockwise, smashing into one another while moving at 99.9999991% the speed of light apiece. At two specific points designed to have the greatest numbers of collisions, enormous particle detectors were constructed and installed: the CMS and ATLAS detectors. After billions upon billions of collisions at these enormous energies, the LHC has brought us further in our hunt for the fundamental nature of the Universe and our understanding of the elementary building blocks of matter.
Earlier this month, the LHC celebrated 10 years of operation, with the discovery of the Higgs boson marking its crowning achievement. Yet despite these successes, no new particles, interactions, decays, or fundamental physics has been found. Worst of all is this: most of CERN’s data from the LHC has been discarded forever.

This is one of the least well-understood pieces of the high-energy physics puzzle, at least among the general public. The LHC hasn’t just lost most of its data: it’s lost a whopping 99.997% of it. That’s right; out of every one million collisions that occurs at the LHC, only about 30 of them have all of their data written down and recorded.
It’s something that happened out of necessity, due to the limitations imposed by the laws of nature themselves, as well as what technology can presently do. But in making that decision, there’s a tremendous fear made all the more palpable by the fact that, other than the much-anticipated Higgs, nothing new has been discovered. The fear is this: that there is new physics waiting to be discovered, but we’ve missed it by throwing this data away.
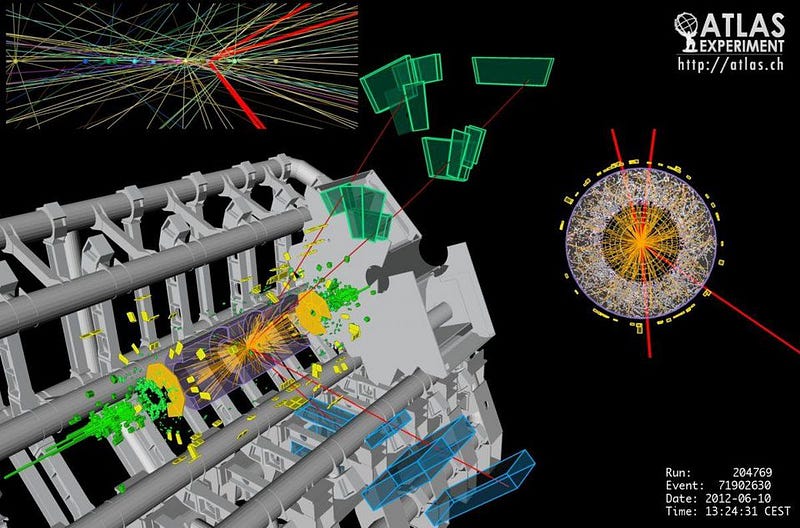
We didn’t have a choice in the matter, really. Something had to be thrown away. The way the LHC works is by accelerating protons as close to the speed of light as possible in opposite directions and smashing them together. This is how particle accelerators have worked best for generations. According to Einstein, a particle’s energy is a combination of its rest mass (which you may recognize as E = mc²) and the energy of its motion, also known as its kinetic energy. The faster you go — or more accurately, the closer you get to the speed of light — the higher energy-per-particle you can achieve.
At the LHC, we collide protons together at 299,792,455 m/s, just 3 m/s shy of the speed of light itself. By smashing them together at such high speeds, moving in opposite directions, we make it possible for otherwise impossible particles to exist.

The reason is this: all particle (and antiparticles) that we can create have a certain amount of energy inherent to them, in the form of their mass-at-rest. When you smash two particles together, some of that energy has to go into the individual components of those particles, both their rest energy and their kinetic energy (i.e., their energy-of-motion).
But if you have enough energy, some of that energy can also go into the production of new particles! This is where E = mc² gets really interesting: not only do all particles with a mass (m) have an energy (E) inherent to their existence, but if you have enough available energy, you can create new particles. At the LHC, humanity has achieved collisions with more available energy for the creation of new particles than in any other laboratory in history.

The energy-per-particle is around 7 TeV, meaning each proton achieves approximately 7,000 times its rest-mass energy in the form of kinetic energy. But collisions are rare and protons aren’t just tiny, they’re mostly empty space. In order to get a large probability of a collision, you need to put more than one proton in at a time; you inject your protons in bunches instead.
At full intensity, this means that there are many tiny bunches of protons going clockwise and counterclockwise inside the LHC whenever it’s running. The LHC tunnels are approximately 26 kilometers long, with only 7.5 meters (or around 25 feet) separating each bunch. As these bunches of beams go around, they get squeezed as they interact at the mid-point of each detector. Every 25 nanoseconds, there’s a chance of a collision.

So what do you do? Do you have a small number of collisions and record every one? That’s a waste of energy and potential data.
Instead, you pump in enough protons in each bunch to ensure you have a good collision every time two bunches pass through. And every time you have a collision, particles rip through the detector in all directions, triggering the complex electronics and circuitry that allow us to reconstruct what was created, when, and where in the detector. It’s like a giant explosion, and only by measuring all the pieces of shrapnel that come out can we reconstruct what happened (and what new things were created) at the point of ignition.

The problem that then arises, however, is in taking all of that data and recording it. The detectors themselves are big: 22 meters for CMS and 46 meters long for ATLAS. At any given time, there are particles arising from three different collisions in CMS and six separate collisions in ATLAS. In order to record data, there are two steps that must occur:
- The data has to be moved into the detector’s memory, which is limited by the speed of your electronics. Even though the electrical signals travel at nearly the speed of light, we can only “remember” about 1-in-500 collisions.
- The data in memory has to be written to disk (or some other permanent device), and that’s a much slower process than storing data in memory; decisions need to be made as to what’s kept and what’s discarded.
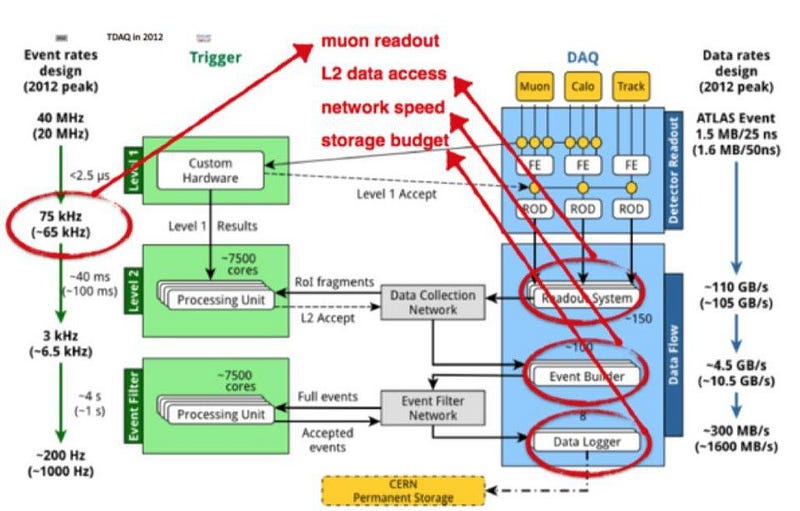
Now, there are some tricks we use to ensure that we choose our events wisely. We look at a variety of factors about the collision immediately to determine if it’s worth a closer look or not: what we call a trigger. If you pass the trigger, you make it to the next level. (A tiny fraction of untriggered data is saved as well, just in case there’s an interesting signal we didn’t think to trigger on.) Then a second layer of filters and triggers is applied; if an event is interesting enough to get saved, it goes into a buffer to ensure it gets written to storage. We can make sure that every event that gets flagged as “interesting” is saved, along with a small fraction of uninteresting events as well.
That’s why, with the necessity of taking both of these steps, only 0.003% of the total data can be saved for analysis.

How do we know we’re saving the right pieces of data? The ones where it’s most likely we’re creating new particles, seeing the importance of new interactions, or observing new physics?
When you have proton-proton collisions, most of what comes out are normal particles, in the sense that they’re made up almost exclusively of up-and-down quarks. (This means particles like protons, neutrons, and pions.) And most collisions are glancing collisions, meaning that most of the particles wind up hitting the detector in the forwards or backwards direction.

So, to take that first step, we try and look for particle tracks of relatively high-energies that go in the transverse direction, rather than forwards or backwards. We try and put into the detector’s memory the events that we think had the most available energy (E) for creating new particles, of the highest mass (m) possible. Then, we quickly perform a computational scan of what’s in the detector’s memory to see if it’s worth writing to disk or not. If we choose to do so, it can be queued to go into permanent storage.
The overall result is that about 1000 events, every second, can be saved. That might seem like a lot, but remember: approximately 40,000,000 bunches collide every second.

We think we’re doing the smart thing by choosing to save what we’re saving, but we can’t be sure. In 2010, the CERN Data Centre passed an enormous data milestone: 10 Petabytes of data. By the end of 2013, they had passed 100 Petabytes of data; in 2017, they passed the 200 Petabyte milestone. Yet for all of it, we know that we’ve thrown away — or failed to record — about 30,000 times that amount. We may have collected hundreds of Petabytes, but we’ve discarded, and lost forever, many Zettabytes of data: more than the total amount of internet data created in a year.

It’s eminently possible that the LHC created new particles, saw evidence of new interactions, and observed and recorded all the signs of new physics. And it’s also possible, due to our ignorance of what we were looking for, we’ve thrown it all away, and will continue to do so. The nightmare scenario — of no new physics beyond the Standard Model — appears to be coming true. But the real nightmare is the very real possibility that the new physics is there, we’ve built the perfect machine to find it, we’ve found it, and we’ll never realize it because of the decisions and assumptions we’ve made. The real nightmare is that we’ve fooled ourselves into believing the Standard Model is right, because we only looked at 0.003% of the data that’s out there. We think we’ve made the smart decision in keeping what we’ve kept, but we can’t be sure. It’s possible that the nightmare is one we’ve unknowingly brought upon ourselves.
This piece has been updated thanks to input from Kyle Cranmer, Don Lincoln, and Daniel Whiteson.
Ethan Siegel is the author of Beyond the Galaxy and Treknology. You can pre-order his third book, currently in development: the Encyclopaedia Cosmologica.