This MIT scientist gave Stephen Hawking his voice — then lost his own

- The synthetic voice that Stephen Hawking used in the second half of his life was modeled after the real-life voice of a scientist named Dennis Klatt.
- In the 1970s and 1980s, Klatt developed text-to-speech systems that were unprecedentedly intelligible, able to capture the subtle ways we pronounce not merely words, but whole sentences.
- The “Perfect Paul” voice that Klatt created was arguably one of the most recognizable voices of the 20th century. In approximately 3,400 years, it might also play a role in humanity’s first interaction with a black hole.
“Can you hear me alright?” I ask Brad Story at the start of a video call. To utter a simple phrase like this, I would learn later, is to perform what is arguably the most intricate motor act known to any species: speech.
But as Story, a speech scientist, points to his ear and shakes his head no, this particular act of speech doesn’t seem so impressive. A technological glitch has rendered us virtually mute. We switch to another modern speech-delivery system, the smartphone, and begin a conversation about the evolution of talking machines — a project that began a millennium ago with magical tales of talking brass heads and continues today with technology that, to many of us, might as well be magic: Siri and Alexa, voice-cloning AI, and all the other speech synthesis technologies that resonate throughout our daily lives.
A brief spell of tech-induced muteness might be the closest many people ever come to losing their voice. That’s not to say voice disorders are rare. About one-third of people in the U.S. suffer a speech abnormality at some point in their lives due to a voice disorder, known as dysphonia. But completely and permanently losing your voice is much rarer, typically caused by factors like traumatic injury or neurological disease.
For Stephen Hawking, it was the latter. In 1963, the 21-year-old physics student was diagnosed with amyotrophic lateral sclerosis (ALS), a rare neurological pathology that would erode his voluntary muscle control over the next two decades to the point of near-total paralysis. By 1979, the physicist’s voice had become so slurred that only people who knew him well could understand his speech.
“One’s voice is very important,” Hawking wrote in his memoir. “If you have a slurred voice, people are likely to treat you as mentally deficient.”
In 1985, Hawking developed a severe case of pneumonia and underwent a tracheotomy. It saved his life but took his voice. Afterward, he could communicate only through a tedious, two-person process: Someone would point to individual letters on a card, and Hawking would raise his eyebrows when they struck the right one.
“It is pretty difficult to carry on a conversation like that, let alone write a scientific paper,” Hawking wrote. When his voice vanished, so too did any hope of continuing his career or finishing his second book, the bestseller that would make Stephen Hawking a household name: A Brief History of Time: From the Big Bang to Black Holes.
But soon Hawking was producing speech again — this time not with the BBC English accent he had acquired growing up in the suburbs northwest of London, but one that was vaguely American and decidedly robotic. Not everyone agreed on how to describe the accent. Some called it Scottish, others Scandinavian. Nick Mason of Pink Floyd called it “positively interstellar.”
No matter the descriptor, this computer-generated voice would become one of the most recognizable inflections on the planet, bridging Hawking’s mind with countless audiences who were eager to hear him speak about the greatest of questions: black holes, the nature of time, and the origin of our universe.
Unlike other famous speakers throughout history, Hawking’s trademark voice was not entirely his own. It was a reproduction of the real-life voice of another pioneering scientist, Dennis Klatt, who in the 1970s and 1980s developed state-of-the-art computer systems that could transform virtually any English text into synthetic speech.
Klatt’s speech synthesizers and their offshoots went by various names: MITalk, KlatTalk, DECtalk, CallText. But the most popular voice these machines produced — the one Hawking used for the last three decades of his life — went by a single name: Perfect Paul.
“It became so well-known and embodied in Stephen Hawking, in that voice,” Story, a professor in the Department of Speech, Language, and Hearing Sciences at the University of Arizona, tells me. “But that voice was really Dennis’ voice. He based most of that synthesizer on himself.”
Klatt’s designs marked a turning point in speech synthesis. Computers could now take text you typed into a computer and convert it into speech in a way that was highly intelligible. These systems managed to closely capture the subtle ways we pronounce not merely words, but whole sentences.
As Hawking was learning to live and work with his newfound voice in the latter half of the 1980s, Klatt’s own voice was becoming increasingly raspy — a consequence of thyroid cancer, which had afflicted him for years.
“He would speak with kind of a hoarse whisper,” says Joseph Perkell, a speech scientist and a colleague of Klatt’s when they both worked within the Speech Communications Group at MIT during the 1970s and 1980s. “It was kind of the ultimate irony. Here’s a man who’s been working on reproducing the speech process and he can’t do it himself.”
The keys of a building a voice
Long before he learned how to build speech with computers, Klatt watched construction workers build buildings when he was a child in the suburbs of Milwaukee, Wisconsin. The process fascinated him.
“He started out as just a really curious person,” says Mary Klatt, who married Dennis after the two met at the Communication Sciences lab at the University of Michigan, where they had offices next to each other in the early 1960s.
Dennis came to Michigan after earning a master’s degree in electrical engineering from Purdue University. He worked hard in the lab. Not everyone may have noticed, however, given his deep tan, his habit of playing tennis all day, and his tendency to multitask.
“When I used to go over to his apartment, he would be doing three things at once,” Mary says. “He would have his headphones on, listening to opera. He would be watching a baseball game. And at the same time, he would be writing his dissertation.”
When the head of the Communication Sciences lab, Gordon Peterson, read Dennis’ dissertation — which was on theories of aural physiology — he was surprised by how good it was, Mary recalls.
“Dennis wasn’t a grind. He worked many long hours, but it was like it was fun, and that’s a true, curious scientist.”
After earning a Ph.D. in communication sciences from the University of Michigan, Dennis joined the faculty of MIT as an assistant professor in 1965. It was two decades after World War II, a conflict that had sparked U.S. military agencies to start funding the research and development of cutting-edge speech synthesis and encryption technologies, a project that continued into peacetime. It was also about a decade after linguist Noam Chomsky dropped his bomb on behaviorism with his theory of universal grammar — the idea that all human languages share a common underlying structure, which is the result of cognitive mechanisms hardwired into the brain.
At MIT, Klatt joined the interdisciplinary Speech Communication Group, which Perkell describes as a “hotbed of research on human communication.” It included graduate students and scientists who had different backgrounds but a common interest in studying all things related to speech: how we produce, perceive, and synthesize it.
In those days, Perkell says, there was an idea that you could model speech through specific rules, “and that you could make computers mimic [those rules] to produce speech and perceive speech, and it had to do with the existence of phonemes.”
Phonemes are the basic building blocks of speech — similar to how letters of the alphabet are the basic units of our written language. A phoneme is the smallest unit of sound in a language that can change the meaning of a word. For example, “pen” and “pin” are phonetically very similar, and each has three phonemes, but they are differentiated by their middle phonemes: /ɛ/ and /ɪ/, respectively. American English has 44 phonemes broadly sorted into two groups: 24 consonant sounds and 20 vowel sounds, though Southerners may speak with one fewer vowel sound due to a phonological phenomenon called the pin-pen merger: “Can I borrow a pin to write something down?”
To build his synthesizers, Klatt had to figure out how to get a computer to convert the basic units of written language into the basic building blocks of speech — and to do it in the most intelligible way possible.
Building a talking machine
How do you get a computer to talk? One straightforward yet mind-numbing approach would be to record someone speaking every word in the dictionary, store those recordings in a digital library, and program the computer to play those recordings in particular combinations corresponding to the input text. In other words, you’d be piecing together snippets like you’re crafting an acoustic ransom letter.
But in the 1970s there was a fundamental problem with this so-called concatenative approach: A spoken sentence sounds much different than a sequence of words uttered in isolation.
“Speech is continuously variable,” Story explains. “And the old idea that, ‘We’ll have somebody produce all of the sounds in a language and then we can glue them together,’ just does not work.”
Klatt flagged several problems with the concatenative approach in a 1987 paper:
- We speak words faster when they are in a sentence compared to in isolation.
- The stress pattern, rhythm, and intonation of sentences sound unnatural when isolated words are strung together.
- We modify and blend together words in specific ways while speaking sentences.
- We add meaning to words when we speak, such as by putting accents on certain syllables or emphasizing certain words.
- There are just too many words, and new ones are coined almost every day.
So Klatt took a different approach — one that treated speech synthesis not as an act of assembly, but one of construction. At the core of this approach was a mathematical model that represented the human vocal tract and how it produces speech sounds — in particular, formants.
Perfecting Perfect Paul
If you had poked your head into Dennis’ MIT office in the late 1970s, you might have seen him — a thin, six-foot-two man in his forties with a grizzled beard — sitting near a table that held encyclopedia-sized volumes stuffed with spectrograms. These pieces of paper were key to his approach to synthesis. As visual representations of the frequency and amplitude of a sound wave over time, they were the North Star that guided his synthesizers toward an increasingly natural and intelligible voice.
Perkell puts it simply: “He would speak into the microphone and then analyze the speech and then make his machine do the same thing.”
That Dennis used his own voice as a model was a matter of convenience, not vanity.
“He had to try to replicate somebody,” Perkell says. “He was the most accessible speaker.”
On these spectrograms, Dennis spent a lot of time identifying and analyzing formants.
“Dennis did a lot of measurements on his own voice on where the formants should be,” says Patti Price, a speech recognition specialist and linguist, and a former colleague of Dennis’ at MIT in the 1980s.
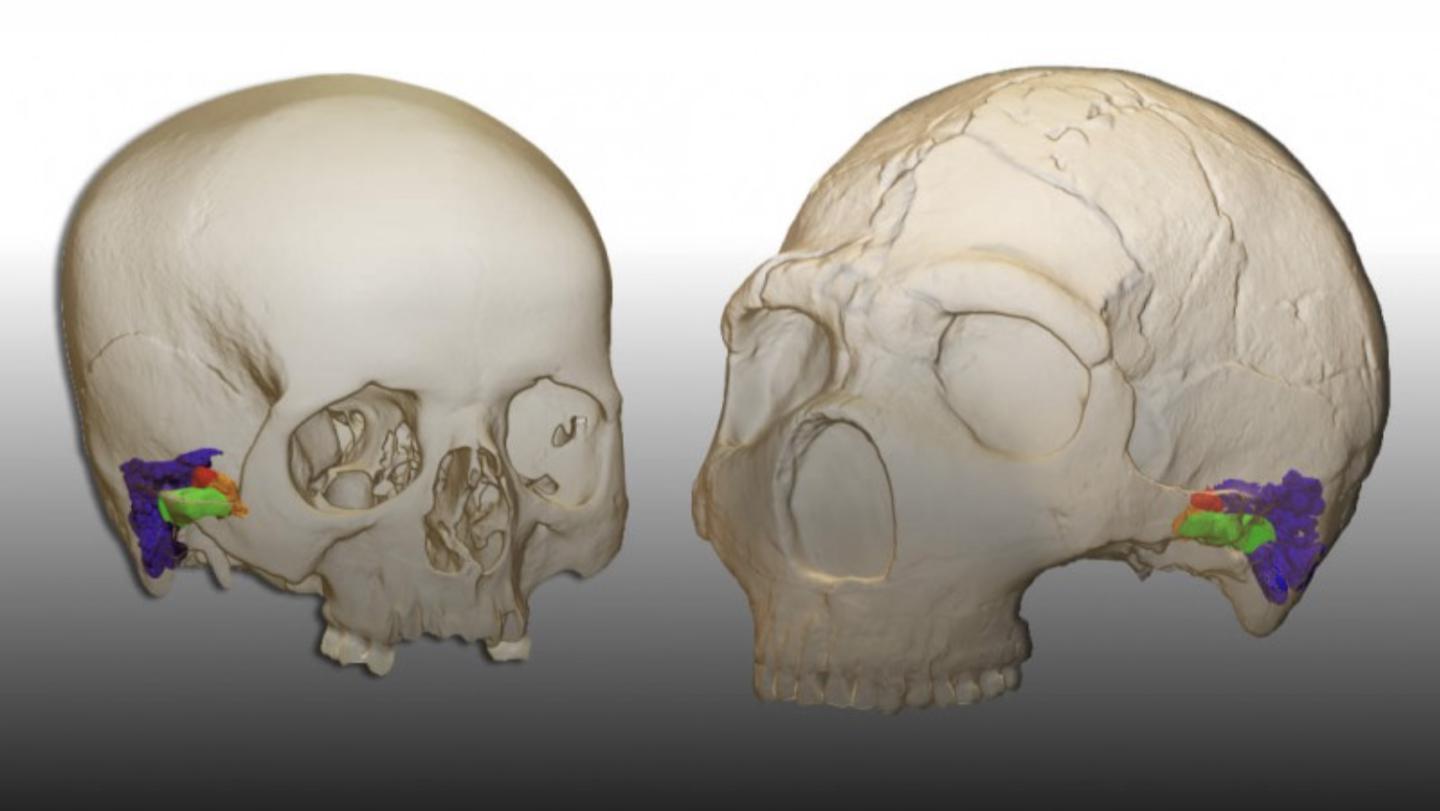
Formants are concentrations of acoustic energy around specific frequencies in a speech wave. When you pronounce the vowel in “cat,” for example, you produce a formant when you drop your jaw low and move your tongue forward to pronounce the “a” vowel sound, represented phonetically as /æ/. On a spectrogram, this sound would show up as several dark bands occurring at specific frequencies within the waveform. (At least one speech scientist, one Perkell says he knew at MIT, can look at a spectrogram and tell you what words a speaker said without listening to a recording.)
“What’s happening, for a particular [vowel or consonant sound], is that there are a set of frequencies that are allowed easy passage through that particular configuration [of the vocal tract], because of the ways that waves propagate through these constrictions and expansions,” Story says.
Why do some frequencies get easy passage? Take the example of an opera singer shattering a wine glass by belting out a high-pitched note. This rare but real phenomenon occurs because the sound waves from the singer excite the wine glass and cause it to vibrate very rapidly. But this only occurs if the sound wave, which carries multiple frequencies, carries one in particular: a resonant frequency of the wine glass.
Every object in the Universe has one or more resonant frequencies, which are the frequencies at which an object vibrates most efficiently when subjected to an external force. Like someone who will only dance to a certain song, objects prefer to vibrate at certain frequencies. The vocal tract is no exception. It contains numerous resonant frequencies, called formants, and these are the frequencies within a sound wave that the vocal tract “likes.”
Dennis’ computer models simulated how the vocal tract produces formants and other speech sounds. Instead of relying on prerecorded sounds, his synthesizer would calculate the formants needed to create each speech sound and assemble them into a continuous waveform. Put another way: If concatenative synthesis is like using Legos to build an object brick by brick, his method was like using a 3D printer to build something layer by layer, based on precise calculations and user specifications.
The most famous product that came out of this approach was DECtalk, a $4,000 briefcase-sized box that you would connect to a computer like you would a printer. In 1980, Dennis licensed his synthesis technology to the Digital Equipment Corporation, which in 1984 released the first DECtalk model, the DTC01.
DECtalk synthesized speech in a three-step process:
- Convert user-inputted ASCII text into phonemes.
- Evaluate the context of each phrase so the computer can apply rules to modify inflection, duration between words, and other modifications aimed at boosting intelligibility.
- “Speak” the text through a digital formant synthesizer.
DECtalk could be controlled by computer and telephone. By connecting it to a phone line, it was possible to make and receive calls. Users could retrieve information from the computer that DECtalk was connected to by pressing certain buttons on the phone.
What ultimately made it a landmark technology was that DECtalk could pronounce virtually any English text, and it could strategically modify its pronunciation thanks to computer models that accounted for the entire sentence.
“That’s really his major contribution — to be able to take literally the text to the speech,” Story said.
Perfect Paul wasn’t the only voice that Dennis developed. The DECtalk synthesizer offered nine: four adult male voices, four adult female voices, and one female child voice called Kit the Kid. All the names were playful alliterations: Rough Rita, Huge Harry, Frail Frank. Some were based on the voices of other people. Beautiful Betty was based on the voice of Mary Klatt, while Kit the Kid was based on their daughter Laura’s. (You can hear some of them, as well as other clips from older speech synthesizers, in this archive hosted by the Acoustical Society of America.)
But “when it came down to the guts of what he was doing,” Perkell says, “it was a solitary exercise.” Of the DECtalk voices, Dennis spent by far the most time on Perfect Paul. He seemed to think it was possible to, well, perfect Perfect Paul — or at least approach perfection.
“According to the spectral comparisons, I’m getting pretty close,” he told Popular Science in 1986. “But there’s something left that’s elusive, that I haven’t been able to capture. […] It’s simply a question of finding the right model.”
Finding the right model was a matter of finding the control parameters that best simulated the human vocal tract. Dennis approached the problem with computer models, but the speech synthesis researchers who came long before him had to work with more primitive tools.
Talking heads
Speech synthesis is all around us today. Say “Hey Alexa,” or “Siri,” and soon you will hear artificial intelligence synthesize human-like speech through deep-learning techniques almost instantaneously. Watch a modern blockbuster like Top Gun: Maverick, and you might not even realize that the voice of Val Kilmer was synthesized — Kilmer’s real-life voice was damaged following a tracheotomy.
In 1846, however, it took a shilling and a trip to the Egyptian Hall in London to hear state-of-the-art speech synthesis. The Hall that year was showing “The Marvelous Talking Machine,” an exhibit produced by P.T. Barnum that featured, as attendee John Hollingshead described, a talking “scientific Frankenstein monster” and its “sad-faced” German inventor.
The glum German was Joseph Faber. A land surveyor turned inventor, Faber spent two decades building what was then the world’s most sophisticated talking machine. He actually built two but destroyed the first in a “fit of temporary derangement.” This wasn’t history’s first report of violence against a talking machine. The thirteenth-century German bishop Albertus Magnus was said to have built not merely a talking brass head — a device other medieval tinkerers had supposedly constructed — but a full-fledged talking metal man “who answered questions very readily and truly when demanded.” The theologian Thomas Aquinas, who was a student of Magnus’, reportedly knocked the idol to pieces because it wouldn’t shut up.
Faber’s machine was called the Euphonia. It looked something like a fusion between a chamber organ and a human, possessing a “mysteriously vacant” wooden face, an ivory tongue, bellows for lungs, and a hinged jaw. Its mechanical body was attached to a keyboard with 16 keys. When the keys were pressed in certain combinations in conjunction with a foot pedal that pushed air through the bellows, the system could produce virtually any consonant or vowel sound and synthesize full sentences in German, English, and French. (Curiously, the machine spoke with hints of its inventor’s German accent, no matter the language.)

Under Faber’s control, the Euphonia’s automaton would begin shows with lines like: “Please excuse my slow pronunciation…Good morning, ladies and gentlemen…It is a warm day…It is a rainy day.” Spectators would ask it questions. Faber would press keys and push pedals to make it answer. One London show ended with Faber making his automaton recite God Save the Queen, which it did in a ghostly manner that Hollingshead said sounded as if it came from the depths of a tomb.
This machine was one of the best speech synthesizers from what could be called the mechanical era of speech synthesis, which spanned the 18th and 19th centuries. Scientists and inventors of this time — notably Faber, Christian Gottlieb Kratzenstein, and Wolfgang von Kempelen — thought the best way to synthesize speech was to build machines that mechanically replicated the human organs involved in speech production. This was no easy feat. At the time, acoustic theory was in its early stages, and the production of human speech still puzzled scientists.
“A lot of [the mechanical era] was really trying to understand how humans actually speak,” says Story. “By building a device like Faber did, or the others, you quickly get an appreciation for how complex spoken language is, because it’s hard to do what Faber did.”
The speech chain
Remember the claim that speech is the most complex motor action performed by any species on Earth? Physiologically, that might well be true. The process starts in your brain. A thought or intention activates neural pathways that encode a message and trigger a cascade of muscular activity. The lungs expel air through the vocal cords, whose rapid vibrations chop the air into a series of puffs. As those puffs travel through the vocal tract, you strategically shape them to produce intelligible speech.
“We move our jaw, our lips, our larynx, our lungs, all in very exquisite coordination to make these sounds come out, and they come out at a rate of 10 to 15 [phonemes] per second,” Perkell says.
Acoustically, however, speech is more straightforward. (Perkell notes the technical difference between speech and voice, with voice referring to the sound produced by the vocal cords in the larynx, and speech referring to the intelligible words, phrases, and sentences that result from coordinated movements of the vocal tract and articulators. “Voice” is used colloquially in this article.)
As a quick analogy, imagine you blow air into a trumpet and hear a sound. What is happening? An interaction between two things: a source and a filter.
- The source is the raw sound produced by blowing air into the mouthpiece.
- The filter is the trumpet, with its particular shape and valve positions modifying the sound waves.
You can apply the source-filter model to any sound: plucking a guitar string, clapping in a cave, ordering a cheeseburger at the drive-thru. This acoustic insight came in the 20th century, and it enabled scientists to boil down speech synthesis to its necessary components and skip the tedious task of mechanically replicating the human organs involved in speech production.
Faber, however, was still stuck on his automaton.
John Henry and visions of the future
The Euphonia was mostly a flop. After the stint at Egyptian Hall, Faber quietly left London and spent his final years performing across the English countryside with, as Hollingshead described, “his only treasure— his child of infinite labour and unmeasurable sorrow.”
But not everyone thought Faber’s invention was a weird sideshow. In 1845, it captivated the imagination of American physicist Joseph Henry, whose work on electromagnetic relay had helped lay the foundation for the telegraph. After hearing the Euphonia at a private demonstration, a vision sparked in Henry’s mind.
“The idea that he saw,” Story says, “was that you could synthesize speech sitting here, at [one Euphonia machine], but you would transmit the keystrokes via electricity to another machine, which would automatically produce those same keystrokes so that someone far, far away would hear that speech.”
In other words, Henry envisioned the telephone.
It might be little wonder, then, that several decades later, Henry helped encourage Alexander Graham Bell to invent the telephone. (Bell’s father had also been a fan of Faber’s Euphonia. He even encouraged Alexander to build his own talking machine, which Alexander did — it could say, “Mama.”)
Henry’s vision went beyond the telephone. After all, Bell’s telephone converted the sound waves of human speech into electrical signals, and then back to sound waves on the receiving end. What Henry foresaw was technology that could compress and then synthesize speech signals.
This technology would arrive nearly a century later. As Dave Tompkins explained in his 2011 book, How to Wreck a Nice Beach: The Vocoder from World War II to Hip-Hop, The Machine Speaks, it came after a Bell Labs engineer named Homer Dudley had an epiphany about speech while lying in a Manhattan hospital bed: His mouth was actually a radio station.
The vocoder and the carrier nature of speech
Dudley’s insight was not that his mouth could broadcast the Yankees game, but rather that speech production could be conceptualized under the source-filter model — or a broadly similar model that he called the carrier nature of speech. Why mention a radio?
In a radio system, a continuous carrier wave (source) is generated and then modulated by an audio signal (filter) to produce radio waves. Similarly, in speech production, the vocal cords within the larynx (source) generate raw sound through vibration. This sound is then shaped and modulated by the vocal tract (filter) to produce intelligible speech.
Dudley wasn’t interested in radio waves, though. In the 1930s, he was interested in transmitting speech across the Atlantic Ocean, along the 2,000-mile transatlantic telegraph cable. One problem: These copper cables had bandwidth constraints and were only able to transmit signals of about 100 Hz. Transmitting the content of human speech across its spectrum required a minimum bandwidth of about 3000 Hz.
Solving this problem required reducing speech to its bare essentials. Luckily for Dudley, and for the Allied war effort, the articulators that we use to shape sound waves — our mouth, lips, and tongue — move slow enough to pass under the 100 Hz bandwidth limit.
“Dudley’s great insight was that much of the important phonetic information in a speech signal was superimposed on the voice carrier by the very slow modulation of the vocal tract by the movement of the articulators (at frequencies of less than about 60 Hz),” Story explains. “If those could somehow be extracted from the speech signal, they could be sent across the telegraph cable and used to recreate (i.e., synthesize) the speech signal on the other side of the Atlantic.”
The electrical synthesizer that did this was called the vocoder, short for voice encoder. It used tools called band-pass filters to break speech into 10 separate parts, or bands. The system would then extract key parameters such as amplitude and frequency from each band, encrypt that information, and transmit the scrambled message along telegraph lines to another vocoder machine, which would then descramble and ultimately “speak” the message.
Starting in 1943, the Allies used the vocoder to transmit encrypted wartime messages between Franklin D. Roosevelt and Winston Churchill as part of a system called SIGSALY. Alan Turing, the English cryptanalyst who cracked the German Enigma machine, helped Dudley and his fellow engineers at Bell Labs convert the synthesizer into a speech encipherment system.
“By the end of the war,” wrote philosopher Christoph Cox in a 2019 essay, “SIGSALY terminals had been installed at locations all over the world, including on the ship that carried Douglas MacArthur on his campaign through the South Pacific.”
Although the system did a good job of compressing speech, the machines were massive, occupying whole rooms, and the synthetic speech they produced was neither especially intelligible nor humanlike.
“The vocoder,” Tompkins wrote in How to Wreck a Nice Beach, “reduced the voice to something cold and tactical, tinny and dry like soup cans in a sandbox, dehumanizing the larynx, so to speak, for some of man’s more dehumanizing moments: Hiroshima, the Cuban Missile Crisis, Soviet gulags, Vietnam. Churchill had it, FDR refused it, Hitler needed it. Kennedy was frustrated by the vocoder. Mamie Eisenhower used it to tell her husband to come home. Nixon had one in his limo. Reagan, on his plane. Stalin, on his disintegrating mind.”
The buzzy and robotic timbre of the vocoder found a warmer welcome in the music world. Wendy Carlos used a type of vocoder on the soundtrack to Stanley Kubrick’s 1971 film A Clockwork Orange. Neil Young used one on Trans, a 1983 album inspired by Young’s attempts to communicate with his son Ben, who was unable to speak due to cerebral palsy. Over the following decades, you could have heard a vocoder by listening to some of the most popular names in electronic music and hip-hop, including Kraftwerk, Daft Punk, 2Pac, and J Dilla.
For speech synthesis technology, the next major milestone would come in the computer age with the practicality and intelligibility of Klatt’s text-to-speech system.
“The introduction of computers in speech research created a new powerful platform to generalize and to generate new, so far, unrecorded utterances,” says Rolf Carlsson, who was a friend and colleague of Klatt’s and is currently a professor at Sweden’s KTH Royal Institute of Technology.
Computers enabled speech synthesis researchers to design control patterns that manipulated synthetic speech in specific ways to make it sound more human, and to layer these control patterns in clever ways in order to more closely simulate how the vocal tract produces speech.
“When these knowledge-based approaches became more complete and the computers became smaller and faster, it finally became possible to create text-to-speech systems that could be used outside the laboratory,” Carlsson said.
DECtalk hits the mainstream
Hawking said he liked Perfect Paul because it didn’t make him sound like a Dalek — an alien race in the Doctor Who series who spoke with computerized voices.
I’m not sure what Daleks sound like, but to my ear Perfect Paul does sound pretty robotic, especially compared to modern speech synthesis programs, which can be hard to distinguish from a human speaker. But sounding humanlike isn’t necessarily the most important thing in a speech synthesizer.
Price says that because many users of speech synthesizers were people with communicative disabilities, Dennis was “very focused on intelligibility, especially intelligibility under stress — when other people are talking or in a room with other noises, or when you speed it up, is it still intelligible?”
Perfect Paul may sound like a robot, but he is at least one that is easy to understand and relatively unlikely to mispronounce a word. This was a major convenience, not only for people with communicative disabilities, but also for those who utilized DECtalk in other ways. The company Computers in Medicine, for example, offered a telephone service where doctors could call a number and have a DECtalk voice read the medical records of their patients — pronouncing medications and conditions — at any time of day or night.
“DECtalk did a better job of speaking these [medical terms] than most laymen do,” Popular Mechanics quoted a computer company executive as saying in a 1986 article.
Reaching this level of intelligibility required crafting a sophisticated set of rules that captured the subtleties of speech. For example, try saying, “Joe ate his soup.” Now do it again but notice how you modify the /z/ in “his.” If you’re a fluent English speaker, you’d probably blend the /z/ of “his” with the neighboring /s/ of “soup.” Doing so converts the /z/ into an unvoiced sound, meaning the vocal cords do not vibrate to produce the sound.
Dennis’ synthesizer could not only make modifications such as converting the /z/ in “Joe ate his soup” into an unvoiced sound, but it could also pronounce words correctly based on context. A 1984 DECtalk advertisement offered an example:
“Consider the difference between $1.75 and $1.75 million. Primitive systems would read this as ‘dollars-one-period-seven-five’ and ‘dollars-one-period-seven-five-million.’ The DECtalk system considers the context and interprets these figures correctly as ‘one dollar and seventy-five cents,’ and ‘one-point-seven-five-million dollars.’”
DECtalk also had a dictionary containing custom pronunciations for words that defy conventional phonetic rules. One example: “calliope,” which is represented phonetically as /kəˈlaɪəpi/ and pronounced, “kuh-LYE-uh-pee.”
DECtalk’s dictionary also contained some other exceptions.
“He told me he put some Easter eggs in his speech synthesis system so that if somebody copied it he could tell that it was his code,” Price says, adding that, if she remembers correctly, typing “suanla chaoshou,” which was one of Klatt’s favorite Chinese dishes, would make the synthesizer say “Dennis Klatt.”
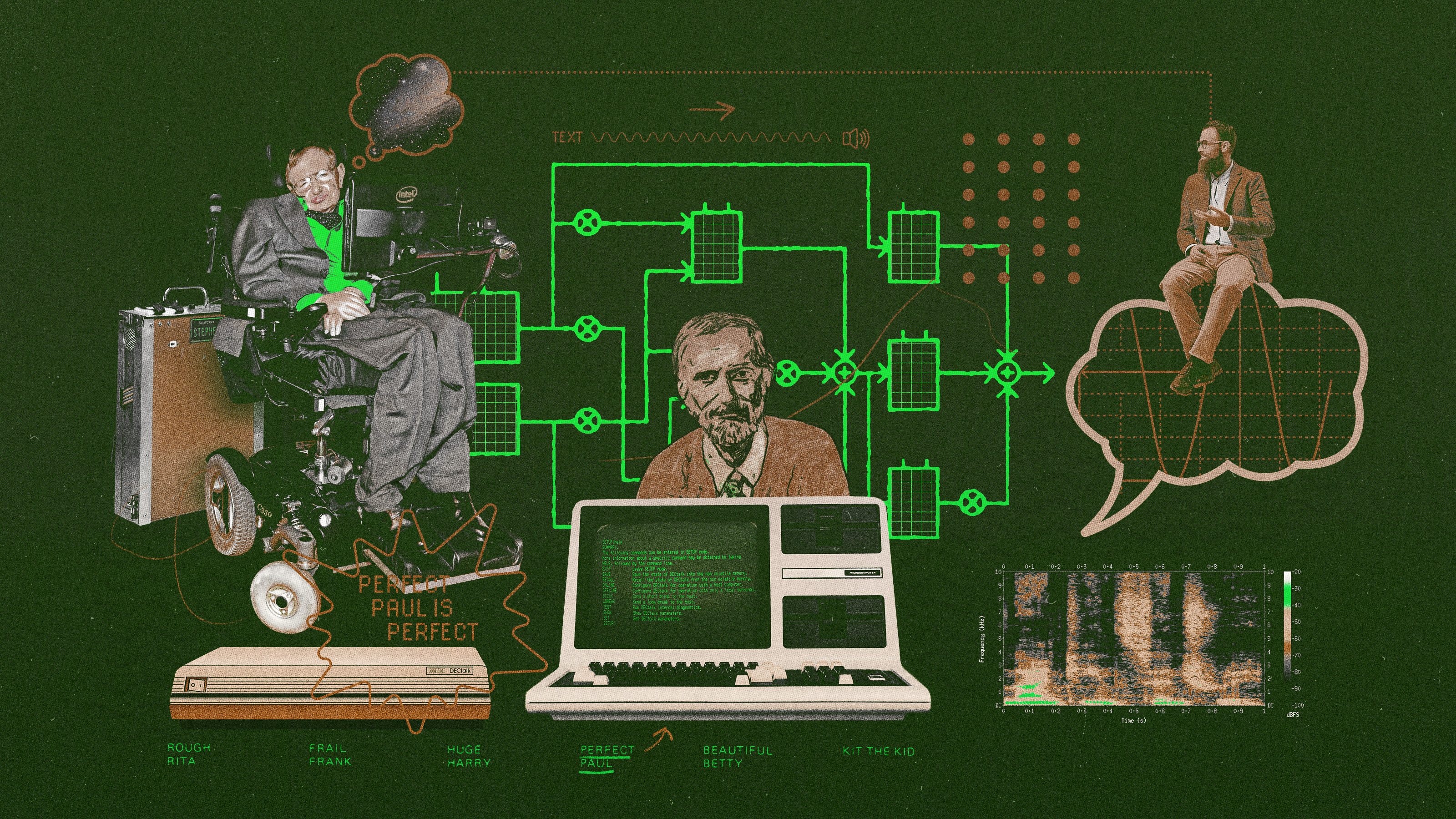
Some of DECtalk’s most important rules for intelligibility centered on duration and intonation.
“Klatt developed a text-to-speech system in which the natural durations between words were pre-programmed and also contextual,” Story says. “He had to program in: If you need an S but it falls between an Ee and an Ah sound, it’s going to do something different than if it fell between an Ooo and an Oh. So you had to have all of those contextual rules built in there as well, and also to build in breaks between words, and then have all the prosodic characteristics: for a question the pitch goes up, for a statement the pitch goes in.”
The ability to modulate pitch also meant DECtalk could sing. After listening to the machine sing New York, New York in 1986, Popular Science’s T.A. Heppenheimer concluded that “it was no threat to Frank Sinatra.” But even today, on YouTube and forums like /r/dectalk, there remains a small but enthusiastic group of people who use the synthesizer — or software emulations of it — to make it sing songs, from Richard Strauss’ Thus Spake Zarathustra to the internet-famous “Trololo” song to Happy Birthday to You, which Dennis had DECtalk sing for his daughter Laura’s birthday.
DECtalk was never a graceful singer, but it’s always been intelligible. One reason that’s important centers on how the brain perceives speech, a field of study to which Klatt also contributed. It takes a lot of cognitive effort for the brain to correctly process poor-quality speech. Listening to it for long enough can even cause fatigue. But DECtalk was “kind of hyper-articulated,” Price says. It was easy to understand, even in a noisy room. It also had features that were particularly useful to people with vision problems, like the ability to speed up the reading of text.
Perfect Paul’s voice in the world
By 1986, the DECtalk synthesizer had been on the market for two years and had seen some commercial success. Dennis’ health was meanwhile dwindling. This twist of fate felt like a “trade with the devil,” he told Popular Science.
The devil must have been OK with the trade’s more benevolent outcomes. As one advertisement touted: “[DECtalk] can give a vision-impaired person an effective, economical way to work with computers. And it can give a speech-impaired person a way to verbalize his or her thoughts in person or over the phone.”
Dennis didn’t start his scientific career with a mission to help disabled people communicate. Rather, he was naturally curious about the mysteries of human communication.
“And then it evolved into, ‘Oh, this really could be useful for other people,’” Mary says. “That was really satisfying.”
In 1988, Hawking was quickly becoming one of the most famous scientists in the world, thanks largely to the surprise success of A Brief History of Time. Dennis was meanwhile aware that Hawking had begun using the Perfect Paul voice, Mary says, but he was always modest about his work and “didn’t go around reminding everybody.”
Not that everyone needed a reminder. When Perkell first heard Hawking’s voice, he says it was “unmistakable to me that that was KlattTalk,” the voice he had regularly heard coming out of Dennis’ MIT office.
Mary prefers not to dwell on the irony of Dennis losing his voice near the end of his life. He was always optimistic, she says. He was a trend-setting scientist who loved listening to Mozart, cooking dinner for his family, and working to illuminate the inner workings of human communication. He kept doing just that until a week before his death in December 1988.
The fate of Perfect Paul
Perfect Paul scored all kinds of speaking roles throughout the 1980s and 1990s. It delivered the forecast on NOAA Weather Radio, provided flight information in airports, voiced the TV character Mookie in Tales from the Darkside and the robotic jacket in Back to the Future Part II. It spoke in episodes of The Simpsons, was featured on the aptly named Pink Floyd song Keep Talking, inspired inside jokes in the online video game Moonbase Alpha, and dropped lines on MC Hawking rap tracks like All My Shootings Be Drivebys. (The real Hawking said he was flattered by the parodies.)
Hawking went on to use the Perfect Paul voice for nearly three decades. In 2014, he was still producing Perfect Paul through 1986 CallText synthesizer hardware, which used Klatt’s technology and the Perfect Paul voice but featured different prosodic and phonological rules than DECtalk. The retro hardware became a problem: The manufacturer had gone out of business, and there was only a finite number of chips left in the world.
So began a concerted effort to save Hawking’s voice. The catch?
“He wanted to sound exactly the same,” Price says. “He just wanted it in software, because one of the original boards had died. And then he got nervous about not having spare boards.”
There had been previous attempts to replicate the sound of Hawking’s synthesizer through software, but Hawking had rejected all of them, including a machine-learning attempt and early attempts from the team that Price worked with. To Hawking, none sounded quite right.

“He used it for so many years that that became his voice and he didn’t want [a new] one,” Price says. “They might have been able to simulate his old voice from old recordings of him, but he didn’t want that. This had become his voice. In fact, he wanted to get a copyright or patent or some protection so that nobody else could use that voice.”
Hawking never patented the voice, though he did refer to it as his trademark.
“I wouldn’t change it for a more natural voice with a British accent,” he told the BBC in a 2014 interview. “I am told that children who need a computer voice want one like mine.”
After years of hard work, false starts, and rejections, the team Price collaborated with finally succeeded in reverse-engineering and emulating the old hardware to produce a voice that, to Hawking’s ear, sounded nearly identical to the 1986 version.
The breakthrough came just months before Hawking died in March 2018.
“We were going to make the big announcement, but he had a cold,” Price says. “He never got better.”
Speech synthesis today is virtually unrecognizable compared to the 1980s. Instead of trying to replicate the human vocal tract in some fashion, most modern text-to-speech systems use deep-learning techniques where a neural net is trained on massive numbers of speech samples and learns to generate speech patterns based on the data it was exposed to.
That’s a far cry from Faber’s Euphonia.
“The way that [modern speech synthesizers] produce speech,” Story says, “is not in any way related to how a human produces speech.”
Some of today’s most impressive applications include voice-cloning AI like Microsoft’s VALL-E X, which can replicate someone’s voice after listening to them speak for only a few seconds. The AI can even mimic the original speaker’s voice in a different language, capturing the emotion and tone, too.
Not all speech scientists necessarily love the verisimilitude of modern synthesis.
“This trend of conversing with machines is very disturbing to me, actually,” Perkell says, adding that he prefers to know he’s talking with a real person when he’s on a phone call. “It dehumanizes the communication process.”
In a 1986 paper, Dennis wrote that it was difficult to estimate how increasingly sophisticated computers that can listen and speak would impact society.
“Talking machines may be just a passing fad,” he wrote, “but the potential for new and powerful services is so great that this technology could have far reaching consequences, not only on the nature of normal information collection and transfer, but also on our attitudes toward the distinction between man and computer.”
When thinking about the future of talking machines, Dennis probably figured that newer and more sophisticated technologies would eventually render the Perfect Paul voice obsolete — a fate that has largely played out. What would have been virtually impossible for Dennis to predict, however, was the fate of Perfect Paul around the 55th century. That’s when a black hole will swallow up a signal of Perfect Paul.
As a tribute to Hawking after his death, the European Space Agency in June 2018 beamed a signal of Hawking speaking toward a binary system called 1A 0620–00, which is home to one of the closest known black holes to Earth. When the signal arrives there, after beaming at the speed of light through interstellar space for some 3,400 years, it will cross the event horizon and head toward the black hole’s singularity.
The transmission is set to be humanity’s first interaction with a black hole.