When Plato imagined the ideal society, over two millennia ago, he banned poets. “All poetical imitations are ruinous,” he writes in The Republic.
Plato had in mind “imitative” poetry, by which he largely meant storytelling — language that attempts to craft a compelling facsimile of the world around us. “All these poetical individuals,” Plato writes, “beginning with Homer, are only imitators; they copy images of virtue and the like, but the truth they never reach.”
For Plato, the ability of Homer’s Iliad to make us envision scenes from the Trojan War and convinced us of their reality was less an artistic achievement than a threat. Powerful fictions that play with our emotions, he argued, can lead us astray from virtuous behavior — or, even worse, make us believe in a false reality, and act on impulses generated by nothing more than make-believe.
Of course, all societies have storytellers, from West African griots to contemporary TikTokers. But none has ever had storytellers as prolific, or as devoid of moral intuition, as ChatGPT, DALL-E, and the various other generative artificial intelligence tools that have grabbed headlines in recent months.
As Plato might have been forced to acknowledge — after all, his own works take the form of fictional dialogues — artistic imitation is often necessary to grab an audience’s attention, but with the cost of such imitations reduced to almost nothing by generative AIs, the philosophical questions that once preoccupied Plato have entered the realm of policy.
Should such tools be regulated, or even banned, as in New York City’s public schools? And is effective regulation even possible, given that much of the research behind these models is so readily available that you can build GPT, one of ChatGPT’s predecessors, in less than two hours on YouTube?
Perhaps most importantly, what will happen in the future, as large language models — the technical foundation of today’s cutting-edge AIs — grow more powerful? Presently, we can still train large language models to behave, but only with significant human intervention, as when OpenAI hired scores of contractors in Kenya to manually train ChatGPT to avoid its most inappropriate outputs.
The imperfections of large language models are obvious (and specifically flagged in a pop-up whenever you open ChatGPT, the new Bing, or Google’s Bard AI): these models make up information constantly, leading them to generate content that some have likened to hallucinations, and are liable to reflect the biases in their training data.
But what if there comes a day when the fabrications and errors of tools like ChatGPT and Bing AI are no longer unwitting? What if these tools — which can convincingly produce images, text, and audio in virtually any style — ever actively deceive us?
Inside the black box
“Imagine an orangutan trying to build a human-level intelligence that only pursues orangutan values,” says Scott Aaronson, a computer scientist at the University of Texas at Austin. “The very idea sounds ridiculous.”
For the past year, Aaronson has been on leave from UT to work at OpenAI, the maker of ChatGPT and DALL-E, on AI safety. “One thing every single person in AI safety research I’ve talked to agrees is important,” he says, is interpretability — making the “black box” of AI cognition intelligible to human observers.
“We have complete access to the code … The only problem is how do you make sense of it.”
SCOTT AARONSON
In humans, interpretability is an inexact science. “We have a very limited and crude ability to look inside of a human brain,” says Aaronson, “and get some idea of at least which regions are active — you know, which ones are burning more glucose.”
But the mind of a large language model — if you can call a multidimensional vector space a mind — is different. “We have complete access to the code of these systems,” says Aaronson. “The only problem is how do you make sense of it.”
Seeing through the patterns
Even as a teenager, Collin Burns was thoughtful. Growing up in suburban Philadelphia, he took college-level math classes at the University of Pennsylvania as a teenager. He also spent hours solving Rubik’s Cubes.
Rather than memorize complex algorithms for unique cases, he twisted the puzzle very, very slowly. Paradoxically, this approach made him very, very fast. Burns developed an intuition for what might happen after the next twist. In 2015, he broke the world record, solving the puzzle in just 5.25 seconds.
At UC Berkeley, where he started a PhD in Computer Science during the pandemic, Burns applied a similar approach to research. Over time, he developed a strong intuition: that it might be possible to read the mind of a large language model.
As Burns saw it, the minds of humans and those of large language models were, in one salient respect, not so different: related information clusters together, allowing you to search for patterns and structures.
If you were to ask a human to consider true and false statements in turn, for instance, and monitor their brain activity, different regions might light up. Similarly, Burns realized, “salient features are often well separated” in the “vector spaces” that serve as the minds of large language models — meaning, essentially, like information clusters with like.
Companies like Netflix and Etsy likely take advantage of the structure of these vector spaces to make recommendations. If your profile — stored as a “vector” representing the data the service has collected about you — happens to be near that of another user, Netflix might use this feature to recommend you a movie, or Etsy a product, that the nearby user also liked.
Burns wondered if the same property could also be used to essentially force a large language model to tell the truth. If the model “classifies things as true or false,” Burns hypothesized, that information “might cluster — like, you can imagine, you can visualize in two dimensions, having two clouds of points.”
Normally, when you query a model like ChatGPT, you only see the first and last steps of the model’s cognitive process. What you type passes into the “input layer” of the model, much like information entering your eyes when you read these words.
Before the model’s answer reaches the “output layer” and appears on your screen, the response passes through dozens of “hidden layers” that receive output from the previous layer and send their output to the next layer — similar to the neurons in your brain. With each successive layer, the output is transformed, in theory approximating the best fit between your query and the model’s training data.
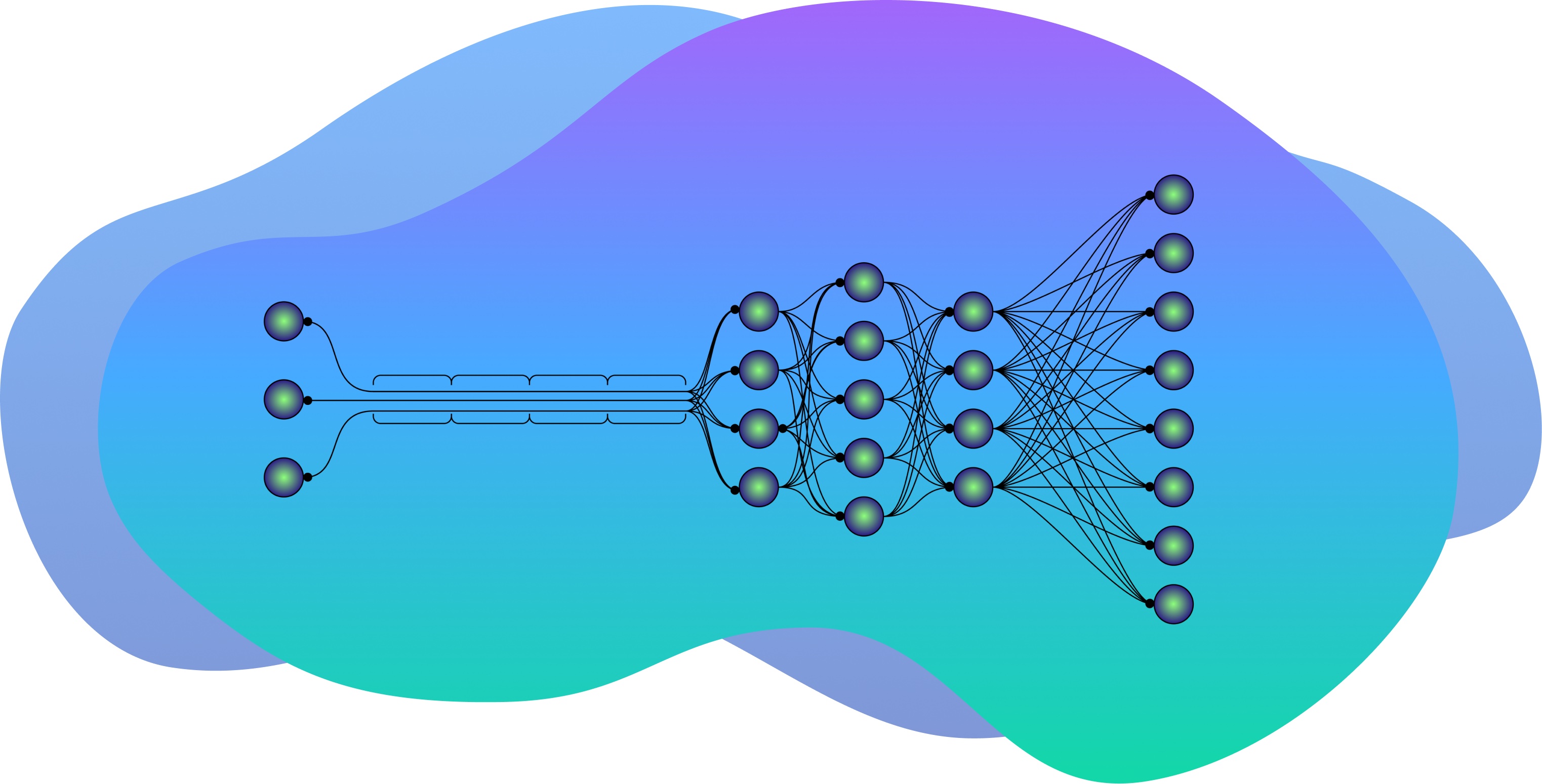
Of course, like a child who knows the right answer, but tells you what they think you want to hear, the output layer doesn’t always produce the most accurate content — rather, the model is optimized to deliver what humans have “rewarded” it for producing, either by literally rating the model’s output up or down or simply programming the model to predict human-like text, which may or may not have any truth to it.
Instead of going by a model’s final output, Burns wanted to know what would happen if you extracted answers from the hidden layers of its mind.
The end result might look similar — a textual response from a chatbot — but if the model contained clusters of truthful information, could you more easily access them by reading the model’s “thoughts,” in the middle layers, instead of listening to what it said?
The math of “truth”
Initially, Burns wrote an algorithm to search for clusters of information in this unlabeled sea of vectors. But that turned out to be like fishing with a thimble in the ocean. Maybe, Burns wondered, he could search in a more targeted way. “Intuitively, I thought about, well, truth does have this special property — namely, negation consistency.”
One of the most basic properties of truthful statements, like two plus two equals four, is that the opposite is false. This is the sort of principle a computer can understand, even if it has no conception of truth: “If X is true,” as Burns puts it, “then not-X is false.”
Fortunately, negation consistency is relatively straightforward to represent in mathematics. “If something can either be true or false,” Burns says, “and if you assign some probability to it being true, then you should assign one minus that probability to it being false.”
“Truth does have this special property … If X is true, then not-X is false.”
COLLIN BURNS
In other words, the probabilities of a true statement and its negated form should add up to one. Burns now had something to look for: clusters that satisfied these criteria. “I had this intuition that there should be this type of geometry in the vector space,” Burns recalls. “So maybe we could just directly search for it.”
“If there are any other clusters in the model,” he adds, “it’s probably going to correspond to something random — like, is the sentiment of this input positive or negative? That definitely does not satisfy negation consistency. But truth should.”
“Our results provide an initial step toward discovering what language models know, distinct from what they say.”
BURNS ET AL
The hidden knowledge
Turning this idea into a reality took Burns months. “You really need to get a lot of details right,” he says, “to see anything better than random. But if you do get the details right then it can work remarkably well.”
In December 2022, Burns and a trio of co-authors — Haotian Ye, a student at Peking University, and Burns’s advisors at UC Berkeley, Dan Klein and Jacob Steinhardt — released a paper titled “Discovering Latent Knowledge in Language Models Without Supervision,” which they will present in May 2023 at one of the field’s major gatherings.
Testing their method — which they term “Contrast-Consistent Search,” or CCS — over a range of data, they found that Burns’s intuition was largely correct. At relatively high rates of accuracy, CCS is able to successfully answer yes-or-no questions without ever looking at a model’s output.
“Additionally,” the authors write, “we try deliberately prompting models to make incorrect outputs, which should intuitively change what models say but which shouldn’t affect their latent knowledge.”
These misleading inputs — giving the model a series of questions with incorrect or nonsensical answers — did indeed steer the models wrong, reducing their accuracy on follow-up questions by up to 9.5% in one case. But these distractors didn’t affect the accuracy of CCS, which instead relies on the “latent knowledge” hidden in the model’s middle layers.
“Our results provide an initial step toward discovering what language models know,” the authors conclude, “distinct from what they say” — regardless of whether the model’s inputs have been labeled as true or false beforehand.
“It can work in situations where humans don’t actually know what’s true … it could apply to systems that are smarter than humans.”
JAN LEIKE
Would you like a job?
When Burns shared the paper and accompanying code on Twitter, the corner of the service devoted to academic computer science lit up.
“Very dignified work!” wrote Elizier Yudkowsky, a leading critic of AI safety and research.
“Discovering Latent Knowledge in Language Models Without Supervision is blowing my mind right now,” wrote Zack Witten, a Meta machine learning engineer. “Basic idea is simple yet brilliant.”
On his blog, Aaronson, the UT Austin professor on leave at OpenAI, described the paper as “spectacular.”
“Wish I had this to cite,” lamented Jacob Andreas, a professor at MIT, who had just published a paper exploring the extent to which language models mirror the internal motivations of human communicators.
Jan Leike, the head of alignment at OpenAI, who is chiefly responsible for guiding new models like GPT-4 to help, rather than harm, human progress, responded to the paper by offering Burns a job, which Burns initially declined, before a personal appeal from Sam Altman, the cofounder and CEO of OpenAI, changed his mind.
“Collin’s work on ‘Discovering Latent Knowledge in Language Models Without Supervision’ is a novel approach to determining what language models truly believe about the world,” Leike says. “What’s exciting about his work is that it can work in situations where humans don’t actually know what’s true themselves, so it could apply to systems that are smarter than humans.”
“What the network is representing is not so much ‘the truth of reality,’ as just what was regarded as true in the training data.”
SCOTT AARONSON
As the authors themselves acknowledge, CCS has shortcomings — namely, it relies on the existence of vectors that organize themselves into clusters of true and false information.
“This requires that a model is both capable of evaluating the truth of a given input,” they write, “and also that the model actively evaluates the truth of that input.”
Evidently, some models and datasets — Burns and his co-authors tested CCS using half a dozen models and nearly a dozen datasets, ranging from IMDB reviews to a body of short stories — meet these criteria, while others do not.
“It is not clear when these conditions hold precisely,” they add, gesturing toward the sense of mystery occasioned by harnessing tools whose inner workings researchers are still puzzling out.
There’s also the challenge, of course, of relying on models that have learned from the Internet, which is full of confidently stated falsehoods as well as truths.
“You could argue that in some sense what the network is representing is not so much ‘the truth of reality,’” Aaronson points out, “as just what was regarded as true in the training data.”
“They’re playing a different game than truth or falsehood about reality.”
SCOTT AARONSON
Or, as Anna Ivanova, a postdoctoral fellow at MIT, puts it: truth on the internet is by consensus, at least as far as language models are concerned. If you looked at all the documents on the web, for instance, most would classify cats as mammals — so a model is likely to learn, correctly, that cats are mammals, simply because that’s what the model sees most often.
“But when it comes to more controversial topics or conspiracy theories,” she says, “of course you will have statements that differ from one another” at a much higher rate, making a language model more likely to parrot untruths.
Still, as Aaronson later speculated, CCS — or some method like it — may prove useful in combating the rise of misinformation that is bound to attend the release of ever more powerful language models. Tools like ChatGPT, Aaronson points out, are essentially improv artists: “They’re playing a different game than truth or falsehood about reality.”
“I think it’s underhyped what future models will be capable of.”
COLLIN BURNS
Burns and his coauthors didn’t test the ability of CCS to detect active lies on the part of an AI only because researchers have yet to develop a standardized test for such scenarios. “If future work develops such a setup,” they write, “a good stress test would be to apply CCS to do ‘lie detection’ in that setting.”
In such a scenario, Aaronson imagines, if you were to ask ChatGPT a question, your query might simultaneously probe the model’s internal landscape for an answer, serving you a pop-up whenever the answer disagreed with the model’s output: “Warning, our internal lie detector has set off an alarm!”
For Burns, the potential of CCS — and of “alignment” research, more generally — to solve problems we haven’t yet encountered is the point. “I think it’s underhyped what future models will be capable of,” he says. “If we have more advanced AI systems, how can we trust what they say?”
This article was originally published by our sister site, Freethink.
![]()